This post summarizes the changes that were made in Substance 5 to address the performance issues raised by the users. As mentioned before (part 1 and part 2), Substance 5 is 2.5-3.5 times faster than Substance 4.3 on various static and dynamic scenarios. Many thanks go to Dmitri Trembovetski from Java2D team for his help and tips.
- Use multi-stop gradients (LinearGradientPaint) with REPEAT cycle method (as mentioned in the comments on Romain’s blog entry).
- Rendering translucent texts is slow and does not use the new native font rasterizer in 6u10. Solution – instead of installing a translucent composite, interpolate the text foreground color and the background fill color based on your alpha value, and use full opacity text rendering.
- BufferedImage.setRGB and BufferedImage.getRGB are really slow. A custom BufferedImageOp might be more difficult to learn, but is much more performant if done correctly.
- Set RenderingHints.KEY_ANTIALIASING to OFF before calling any Graphics.fill operation that results in aliased fill in any case. This is especially relevant for Graphics.fillRect that gets integer parameters. Java2D is not smart enough (yet) to choose the non-antialiased path when the end result is non-antialiased.
- Intermediate non-cached BufferedImages are slow. Whenever possible, either draw directly on the Graphics context, or collect the final result into one BufferedImage that goes into the cache, even if the cache key is more complex.
- Filling with translucent color or filling under translucent composite is very expensive. In fact, the single largest performance gain (20% of the final result) in Substance 5 was removing watermarks from most core skins.
- Use AffineTransform for rotating painting instead of doing it manually. As with BufferedImageOp, it takes some time to understand how to do it (and i’m still terrible at it), but the performance is much better.
- Use EnumSet and EnumMap whenever possible. This is not Java2D-specific, and the tip goes to Joshua Bloch. These are quite faster than Hash* counterparts.
- Do not do multiplt rendering of the same surfaces. This is especially relevant for tables thatcan have potentially thousands of visible cells on the screen. Try to draw background fills and gradients once per table.
- Last, and not specific to Java2D – profile every scenario, question every method and every line of code.
More tips on Java2D performance right here.
Update: hitting “Submit” too fast, i forgot another Swing-specific optimization. Since everything UI-relates has to run on EDT, you can use non-synchronized non-thread safe code and collections. This comes in quite handy coupled with caching images and additional otherwise guarded blocks.
As i was looking at the directions to a store on Google maps, i noticed that they’ve added a new functionality to click on each route turn point and see the “street view” shots. Here is how one of the exits off highway 87 looks on Google:
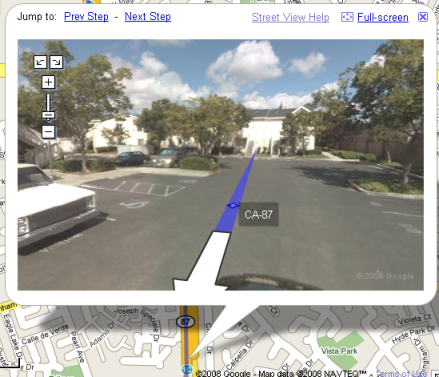
and if you manage to find your way through the parking lot, you’ll just need to drive through another house to get to Santa Teresa:
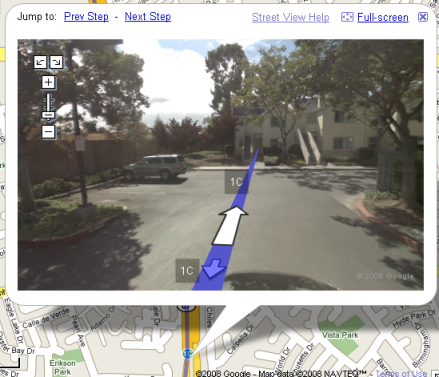
Reminds me of an episode in “The Office” where the boss drove the car into the lake a couple of yards before the bridge, just because the GPS lady told him to :)
Update: deciding to go a little bit further to Santa Teresa, Google would like you to go against the traffic:
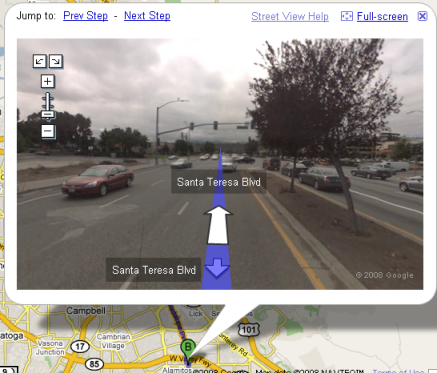
and once you make it to the intersection, turn on red:
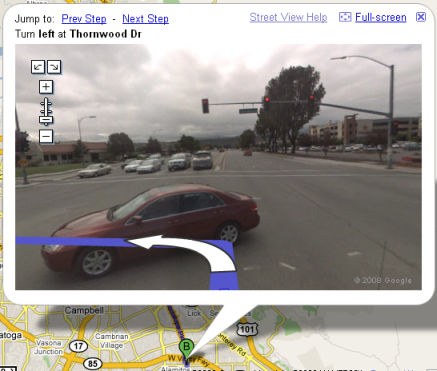
A prolific blogger, a frequent presenter at conferences and a tireless advocate of Groovy. Meet Andres Almiray as the interview series on Swing, RIA, JavaFX and related topics that started with Amy Fowler, Mikael Grev, David Qiao and Chet Haase continues.
Tell us a little bit about yourself. 
I’m a software geek who prefers Java/Groovy to do his work, I’ve been hooked into computer graphics since college (being able to use both SGI workstations and PowerMacs helped a lot), which also explains why I picked Java since the early beginnings. But life has a way to move you to places you didn’t expected at first, so I have my share of years behind server development and web applications (PHP and Perl included, yikes!), I even managed to get some ActionScript somewhere in between. These days I’m back to desktop, my day job being mostly related to Swing development at Oracle, my free time devoted to Groovy related projects like GraphicsBuilder (a Java2D builder) that complements SwingBuilder, and other open source related initiatives.
What do you think about Sun’s new direction of client Java towards RIA space with JavaFX?
I think it is about time Sun really cared about the desktop, I’ve been waiting for something like this since Swing came out. The good news is that some AWT/Swing APIs will be updated, as we have seen lately non-rectangular, translucent windows are finally available, while at the same time new APIs have been added like project SceneGraph and JWebPane, smaller JRE and faster applets too. I gladly welcome all those upgrades. But I don’t buy it on JavaFX Script just yet, I have to admit I’m biased on this one being a Groovy developer, as almost everything that JavaFX Script offers I can do with Groovy, the only thing not possible (today) is binding to any expression, which I consider the sole benefit to switch over JavaFX Script, it is really that powerful. But who knows, nothing is set on stone, I might code real applications with it at some point in the future.
Over the last year we have seen a growing number of projects using Swing as a backbone for new UI scripting languages. This includes Groovy, Scala, Jython, JRuby and, of course, JavaFX. Should this be the future of Swing – relegated to be just a foundation layer?
Let’s face it, compared to those other languages Swing in plain Java is too verbose, which is perhaps why so many developers would rather tango with visual tools and code generators in the first place. I believe in polyglot programming, thankfully I’m not restricted to code in just one language to rule over all my applications. Swing as a foundation layer makes sense, but considering that some of those languages provide a way to enhance existing Java classes (even in runtime) you may bend the foundation to your needs.
What are Swing’s weak points, and how are they addressed in Groovy’s SwingBuilder?
Besides it being verbose because of the Java language itself, I would say threading, it is so easy to shoot yourself in the foot with threading issues, you have to constantly remind yourself in which thread your code will be executed. Groovy’s SwingBuilder addresses the first point with Groovy itself. With native syntax for List and Maps, property access on beans, safe reference navigation and GPath, closures and metaprogramming, you have a full set of new tools to code less while retaining the same behavior. The second one is explicit to the builder as it exposes a set of methods that deal with threading in a very simple way. Say you write an ActionListener, as you now all listeners are called on the EDT, in this case the handling code will perform a long task and update the ui when it finishes. The usual solution in plain Java would be to call SwingUtilities.[invokeLater|invokeAndWait] with a Runnable as parameter, which means you have to create a new class, even if it is an inner anonymous one. With SwingBuilder you could do something like this

Do you feel constrained by the internals of Swing?
I consider myself a regular Swing developer, so far I’ve never had the need to meddle with a RepaintManager nor other scary/gory Swing internals, I leave that to the experts like you.
Both JavaFX and Groovy’s SwingBuilder provide access to Swing components and full APIs. Is this a desired feature for migrating existing applications, or perhaps this access should be restricted to enforce a cleaner design and not add yet another way on top of all that Swing carries with it over the past ten years?
There is a slight difference, JavaFX Script relies on Swing wrappers, those wrappers give JavaFX Script better control on Swing components. On the other hand Groovy’s SwingBuilder uses Swing classes as is. Groovy is able to dynamically enhance (both at compile time and runtime) said Swing classes, if needed be, thanks to its metaprogramming facilities. In the end JavaFX has a thin layer of abstraction that may be used as an extension point (in the future) without needing to actually change any Swing class, while Groovy itself can be used at any time to extend those classes. Back on your question both approaches already add something on top of Swing in some way but they clearly do not restrict access in any way, I believe design in Swing can be clean, it just takes too much lines of code to get to that point.
What do you think about visual designers? Should we encourage their use for beginner developers, even at the price of hiding the API internals and creating possible maintenance problems?
Perhaps I’m old-school as I have always preferred VI/command line tools over IDEs and designers, but I would say yes. Let beginners use a visual tool to feel more confident while starting out, but at the same time encourage them to look under the hood and get acquantied with the generated code, so that they may understand it, and later be able to tweak it by hand when and where it makes sense.
What do you think about blurring the lines between business and consumer applications? Should a business application look sleek just because everybody else is doing it?
Should we all fall from a cliff as lemmings do? of course not =). I’m with Chet Haase on this one, snazzy and springy effects do not belong on a business application in most cases, but using animation as a feedback is a powerful tool, perhaps it is a glow effect on a button or a translucent dialog/blurred background combination to focus the user’s attention into a recent change or a part of the UI that requires interaction at that precise moment.
What are your thoughts on breaking compatibility to correct old mistakes and provide a better designed UI toolkit?
If it makes development and a reasonable (by reasonable understanding perhaps a ratio of lines of code to change mixed with the amount of testing that has to be done) migration path for existing applications for which source code is available I would say yes, go for it. I’m sorry for those people that would like to use newer versions of the JRE but remain forever in compatibility mode, compromises have to be made if you are willing to play with new toys.
Is there anything else you would like to add?
Don’t write off desktop apps just yet given that many have jumped into the web bandwagon. Webapps have been copying desktop apps since the very beginning, and now desktop apps are catching up, after all Ben Galbraith said a year ago “Web is becoming ‘desktopy’, Desktop is becoming ‘weby'” (or something close to that) and I believe he is right.
